Screaming Frog(中文名“尖叫青蛙”,以下簡稱“青蛙”),是一個我們在日常工作中使用得非常頻繁的工具,如果讓我用一句話來概括“青蛙”的功能,我覺得:
“它是一個通過模擬搜索引擎爬蟲,來抓取并分析網(wǎng)站中各式各樣的信息和內(nèi)容的工具。”
相比于人工檢查網(wǎng)站,“青蛙”的核心優(yōu)勢在于:
效率高:它可以快速抓取大量頁面,并自動分析數(shù)據(jù),而人工檢查網(wǎng)站則需要耗費大量時間和精力;
全面性:它可以檢測到人工檢查容易遺漏的網(wǎng)站問題,例如內(nèi)鏈問題、代碼錯誤等;
客觀性:它的分析結(jié)果是基于數(shù)據(jù)的,因此更加客觀、公正;
可持續(xù)性:它可以定期自動檢測網(wǎng)站問題,幫助網(wǎng)站運營人員持續(xù)監(jiān)控網(wǎng)站健康狀況。
由于“青蛙”抓取的對象是“網(wǎng)站”,而“網(wǎng)站”是包括“自己網(wǎng)站”和“其它網(wǎng)站”的,所以我們在使用“青蛙”時,不僅可以用來自檢,也能用于競品分析。
因此,這篇文章會從“自檢”和“競品分析”兩個維度,來跟大家分享一下,我們是如何使用“青蛙”來解決網(wǎng)站SEO問題和提升效率的。
使用“青蛙”來自檢
【需求背景】
內(nèi)鏈,是將用戶和搜索引擎爬蟲引導(dǎo)至網(wǎng)站上其它頁面的重要橋梁,因此對于網(wǎng)站的SEO非常重要。
而404錯誤內(nèi)鏈,會導(dǎo)致這個橋梁的中斷,因此我們必須定期去修復(fù)網(wǎng)站中的錯誤內(nèi)鏈。
然而,通過人工去一個頁面一個頁面的找,肯定是不太現(xiàn)實的,耗時耗力,效率太低。
【解決辦法】通過查找被抓取頁面中,返回狀態(tài)碼為404的頁面,篩選出哪些頁面存在404錯誤內(nèi)鏈,并快速定位這些錯誤內(nèi)鏈所處頁面中的位置。
排查網(wǎng)站中使用JS生成的重要內(nèi)容
【需求背景】
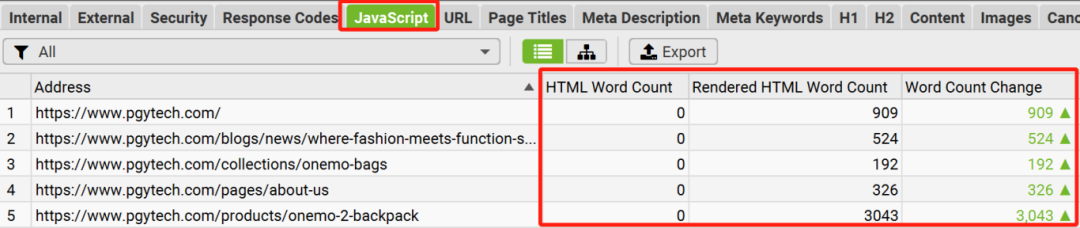
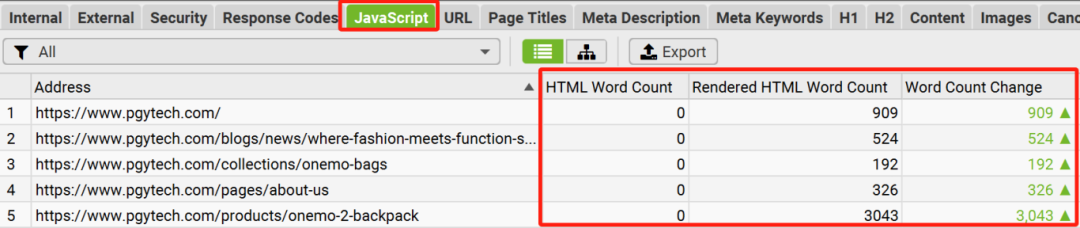
Javascript 可以讓用戶跟網(wǎng)站的交互非常豐富,提升用戶體驗。因此,對于如今的網(wǎng)站而言,Javascript 的應(yīng)用非常普遍。
但是,對于搜索引擎爬蟲而言,重要的內(nèi)容(例如內(nèi)鏈,文字),如果是通過Javascript來動態(tài)生成的話,會使得搜索引擎對頁面的快速加載及完整渲染產(chǎn)生問題,從而導(dǎo)致頁面排名不佳的后果。
【解決辦法】通過在“青蛙”的設(shè)置中,啟用Javascript渲染功能,來對比啟用該功能前后的文字內(nèi)容結(jié)果差異,來快速判斷自己的網(wǎng)站是否有嚴(yán)重的Javascript渲染問題,從而確定網(wǎng)站Javascript SEO優(yōu)化的優(yōu)先級。
定期自動生成XML Sitemap
【需求背景】
如果你的網(wǎng)站是自建站,而不是使用常見的CMS平臺(例如Wordpress或Shopify)的話,就很有可能要定期手動生成Sitemap文件。
市面上的確有很多的XML Sitemap生成工具,但是要做到自動、定期且免費生成的話,可能是沒有的。
【解決辦法】通過使用“青蛙”的“定期執(zhí)行”功能,就可以設(shè)置工具在后臺定期運行并生成XML Sitemap(同時包括圖片Sitemap)。
使用“青蛙”來做競品分析
【需求背景】
通過分析核心競品的網(wǎng)站架構(gòu),我們能夠快速的梳理出,自己的網(wǎng)站和競品的網(wǎng)站在內(nèi)容版塊上的差距,以及競品的內(nèi)容策略(在哪個版塊上投入內(nèi)容資源多)。
從而有的放矢,完善自己網(wǎng)站的內(nèi)容營銷策略。
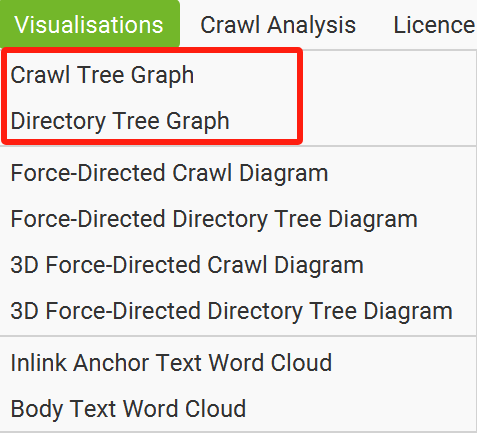
【解決辦法】通過使用“青蛙”的“可視化”功能,選擇不同的展示方式(樹型結(jié)構(gòu)展示和目錄型結(jié)構(gòu)展示),就能將“青蛙”抓取到的網(wǎng)站頁面信息,以更加結(jié)構(gòu)化、形象化的方式展示出來。
總的來說,“樹形結(jié)構(gòu)”方便我們快速了解競品網(wǎng)站的“邏輯結(jié)構(gòu)”,競品最看重的頁面是哪些(最短路徑)。
而“目錄型結(jié)構(gòu)”,方便我們快速了解競品網(wǎng)站的“物理結(jié)構(gòu)”,競品在內(nèi)容分類上的規(guī)劃是怎么樣的,競品重點投入的內(nèi)容類型是什么,從而讓我們?nèi)パa(bǔ)足自身網(wǎng)站缺失的內(nèi)容部分。
如何抓取競品指定頁面類型
【需求背景】
當(dāng)我們發(fā)現(xiàn)競品在某個特殊模塊下(子域名或子文件夾),其內(nèi)容特別多的話,就值得我們?nèi)ド钊敕治鲆幌隆?/p>
如果競品網(wǎng)站體量很大,我們并不想浪費時間抓取和篩選非必要頁面時,就需要限定“青蛙”的抓取范圍。
【解決辦法】通過在“青蛙”的抓取配置中限制URL規(guī)則,就可以實現(xiàn)只抓取感興趣的網(wǎng)站頁面類型。
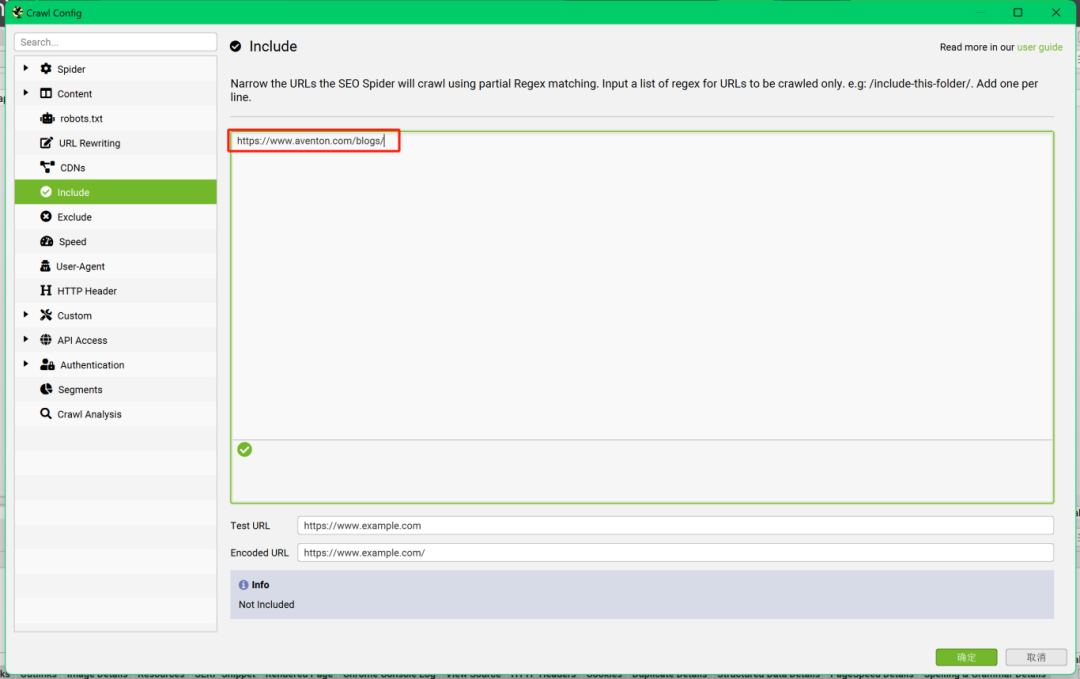
如何抓取競品指定內(nèi)容
【需求背景】
當(dāng)我們需要分析競品網(wǎng)站上特定位置的信息(例如產(chǎn)品信息,價格),來輔助優(yōu)化自己的網(wǎng)站,或是輔助決策時,很難在市面上找到一款工具能做到,因為每個人想要抓取內(nèi)容的場景非常不一樣,定制化程度非常高,所以沒有一款標(biāo)準(zhǔn)化產(chǎn)品能解決類似需求。
【解決辦法】通過使用“青蛙”的“Custom Extraction”功能,在抓取規(guī)則中,填入競品頁面中想要抓取內(nèi)容位置的Xpath路徑,來達(dá)到批量抓取同類型頁面指定位置內(nèi)容的目的。
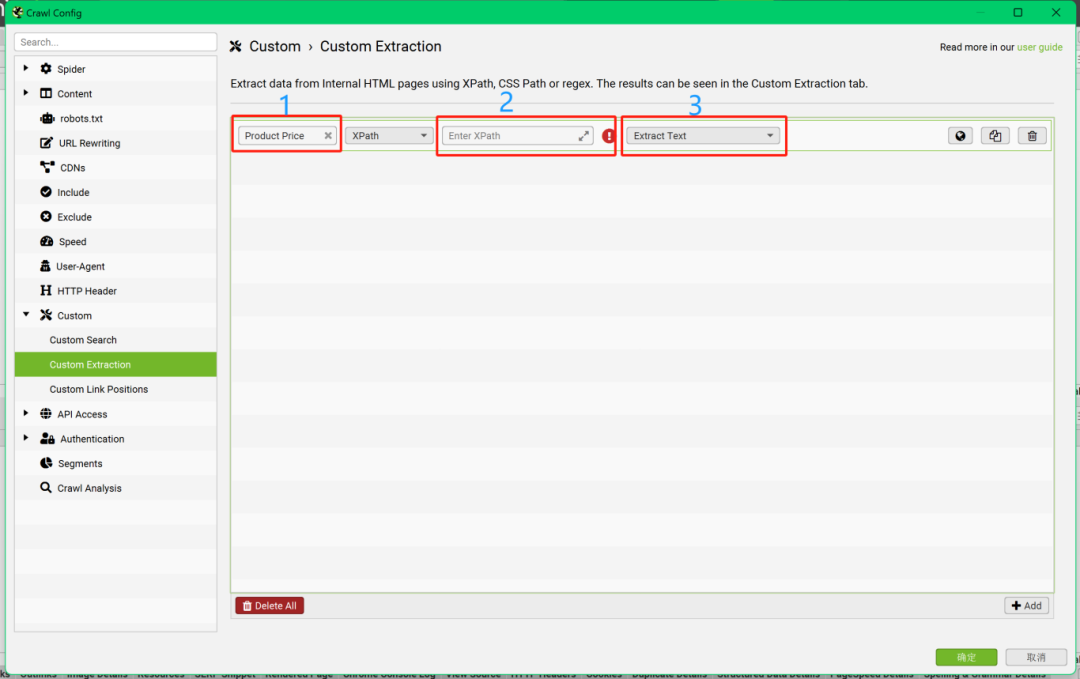
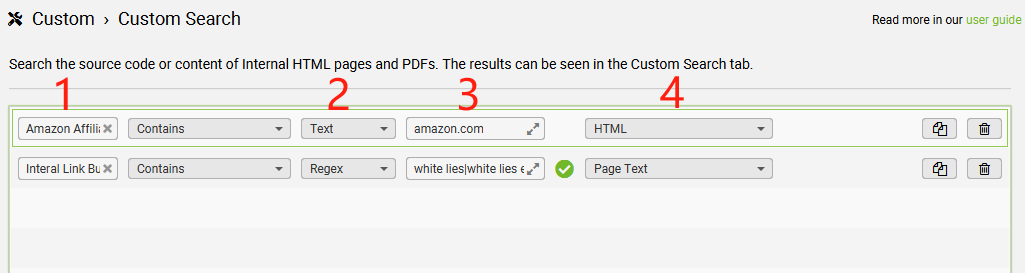
如何搜索競品頁面中的指定內(nèi)容
【需求背景】
當(dāng)我們想查看某網(wǎng)站上是否存在某Affiliate平臺的鏈接,或者是查找是否存在為自己的某個關(guān)鍵詞建設(shè)外鏈的機(jī)會,都可以通過搜索這個網(wǎng)站上,是否存在某個特定的文字來解決類似問題。
【解決辦法】通過利用“青蛙”的“Custom Search”功能,我們可以自定義想在網(wǎng)站中查找的內(nèi)容。
它不僅可以在頁面中搜索文本,還能在HTML代碼中搜索代碼片段(例如鏈接地址)。